After having done the same with the Rouse's Grammar, Im currently working on a project to OCR the Stedman Modern Greek Matery (https://books.google.com.mx/books?id=Rh ... edir_esc=y) into a complete html document. The OCR process is complete, and I'm currently working through the garbage in the document and trying to make a presentable html file. Stedman is written in good katharevousa and has interesting stories using modern vocabulary, even if I do not agree with his pedagogy.
If anyone would like to participate in this work, what is the correct process to create a colabration?
Stedman Project
-
Peitho

- Textkit Neophyte
- Posts: 16
- Joined: Fri Jun 03, 2016 12:36 am
Re: Stedman Project
Cool! I’m glad someone is doing this important work.
I’m curious about the current state of the world of Ancient Greek OCR. I tried submitting a request to the Lace project, adding Pharr’s “Homeric Greek” to the spreadsheet they use to track requests: https://docs.google.com/spreadsheets/d/ ... Ui5tjF6DLo …but about a week and a half later, the website for Lace has vanished without a trace: http://heml.mta.ca/lace/ Do you know what happened to that project? And, failing that, what are the best tools to use for Ancient Greek OCR in 2018 (particularly for mixed Greek/English texts)? Thank you!
I’m curious about the current state of the world of Ancient Greek OCR. I tried submitting a request to the Lace project, adding Pharr’s “Homeric Greek” to the spreadsheet they use to track requests: https://docs.google.com/spreadsheets/d/ ... Ui5tjF6DLo …but about a week and a half later, the website for Lace has vanished without a trace: http://heml.mta.ca/lace/ Do you know what happened to that project? And, failing that, what are the best tools to use for Ancient Greek OCR in 2018 (particularly for mixed Greek/English texts)? Thank you!
-
EberP
- Textkit Neophyte
- Posts: 10
- Joined: Thu Sep 27, 2018 7:02 pm
Re: Stedman Project
Hello Peitho,
This is the best tool to work with OCR: https://github.com/tesseract-ocr/tesseract. If you have any more inquries I'm pretty sure there are people, here in the foroum, more experienced with OCR than I, but I will be also glad to help you in whatever I can.
If you like to assist me in the Stedman Project let me know (this is a link to the current status of the project:
https://melainatigris8.wordpress.com/fe ... velopment/) follow the link to the HTML page.
Thank You, Sincerely Eber.
This is the best tool to work with OCR: https://github.com/tesseract-ocr/tesseract. If you have any more inquries I'm pretty sure there are people, here in the foroum, more experienced with OCR than I, but I will be also glad to help you in whatever I can.
If you like to assist me in the Stedman Project let me know (this is a link to the current status of the project:
https://melainatigris8.wordpress.com/fe ... velopment/) follow the link to the HTML page.
Thank You, Sincerely Eber.
-
Peitho
- Textkit Neophyte
- Posts: 16
- Joined: Fri Jun 03, 2016 12:36 am
Re: Stedman Project
Cool, thanks!
-
Peitho
- Textkit Neophyte
- Posts: 16
- Joined: Fri Jun 03, 2016 12:36 am
Re: Stedman Project
(Mods: feel free to move my questions to a different thread so I don’t threadjack this one)
I’ve been reading a few articles, here:
Deep Learning based Text Recognition (OCR) using Tesseract and OpenCV | Learn OpenCV
Understanding LSTM Networks -- colah's blog (for some technical background)
Training Tesseract for Ancient Greek OCR (PDF)
I guess what I want to know is… where do I start?! I’m using Ubuntu MATE 18.04, I know my way fairly well around the command line, I’ve installed the “tesseract” and “tesseract-ocr-script-grek” packages, and I cloned the git repository at https://ancientgreekocr.org/grctraining.git. It’s hard to find any kind of “how to use Tesseract” articles online, though, that don’t assume a lot of knowledge already. I have basic questions, like… which command-line options are relevant to my use-case? Will I need to train the OCR engine (in which case, where does the training data persist? How is it invoked?), or will I be using data from that repository, or some combination of the two? etc. etc. Thanks!
I’m using Ubuntu MATE 18.04, I know my way fairly well around the command line, I’ve installed the “tesseract” and “tesseract-ocr-script-grek” packages, and I cloned the git repository at https://ancientgreekocr.org/grctraining.git. It’s hard to find any kind of “how to use Tesseract” articles online, though, that don’t assume a lot of knowledge already. I have basic questions, like… which command-line options are relevant to my use-case? Will I need to train the OCR engine (in which case, where does the training data persist? How is it invoked?), or will I be using data from that repository, or some combination of the two? etc. etc. Thanks!
I’ve been reading a few articles, here:
Deep Learning based Text Recognition (OCR) using Tesseract and OpenCV | Learn OpenCV
Understanding LSTM Networks -- colah's blog (for some technical background)
Training Tesseract for Ancient Greek OCR (PDF)
I guess what I want to know is… where do I start?!
-
jeidsath

- Textkit Zealot
- Posts: 5342
- Joined: Mon Dec 30, 2013 2:42 pm
- Location: Γαλεήπολις, Οὐισκόνσιν
Re: Stedman Project
Once you've installed the polytonic Greek support for tesseract, it's something like this:
tesseract <pdfname> -l grc+eng output.txt
Beyond that, you'll need to go to the tesseract documentation.
tesseract <pdfname> -l grc+eng output.txt
Beyond that, you'll need to go to the tesseract documentation.
“One might get one’s Greek from the very lips of Homer and Plato." "In which case they would certainly plough you for the Little-go. The German scholars have improved Greek so much.”
Joel Eidsath -- jeidsath@gmail.com
Joel Eidsath -- jeidsath@gmail.com
-
Peitho
- Textkit Neophyte
- Posts: 16
- Joined: Fri Jun 03, 2016 12:36 am
Re: Stedman Project
How?jeidsath wrote:Once you've installed the polytonic Greek support for tesseract
I’ve installed OCRFeeder, though, per the advice here: Ancient Greek OCR on Linux I’ve gotten it started, creating a project with my PDF of Pharr’s “Homeric Greek.” I don’t really have any idea how to point it to the Ancient Greek training data, though let alone get it to recognize something as mixed English and polytonic Greek. Anyway, thanks for y’alls continued help!
-
Peitho
- Textkit Neophyte
- Posts: 16
- Joined: Fri Jun 03, 2016 12:36 am
Re: Stedman Project
Okay, I think I got it going. OCRFeeder had too many issues, so here I’m using gImageReader as the frontend.

So, as you can see, the main problem I have now is that while recognition for stretches of Ancient Greek text is great, individual Greek words followed by English text (as in the vocabulary lists) are often scanned as English. I’m curious if there’s a way to ameliorate this.
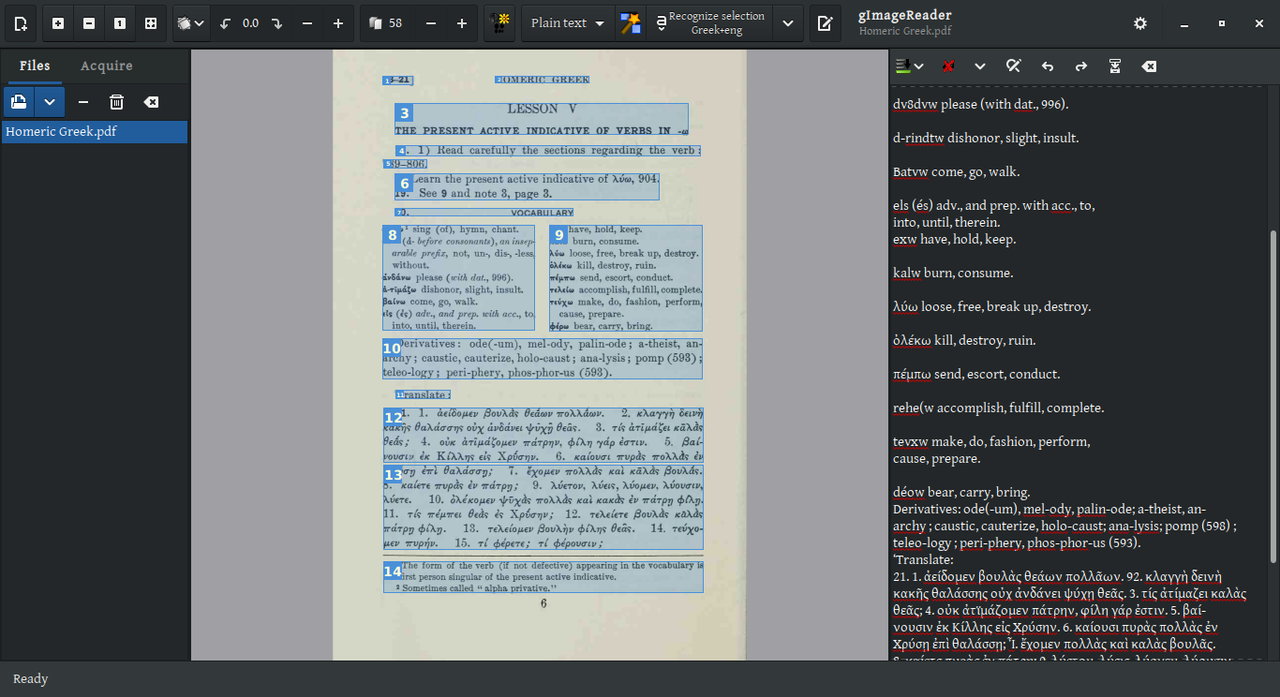
So, as you can see, the main problem I have now is that while recognition for stretches of Ancient Greek text is great, individual Greek words followed by English text (as in the vocabulary lists) are often scanned as English. I’m curious if there’s a way to ameliorate this.
-
hotcajun
- Textkit Neophyte
- Posts: 28
- Joined: Sat Jul 24, 2010 5:35 pm
Re: Stedman Project
From the documentation in the front-end you are using:
This leads me to believe that you could perhaps mark the initial words of the vocab sections for greek-only recognition. If you dig down into that functionality (and share what you find), that might be a potential way to get what you needIf multiple pages are selected for recognition, the program allows the user to choose between either recognizing the full resp. manually selected area for each individual page, or performing a page-layout analysis on each page to automatically detect appropriate recognition areas.